Pong 002
Why Stop At One Agent?
Adam Price
April 3rd 2020
In the previous pong post, I pledged to increase the complexity of our pong environment. So, let us start by tackling this particular predicament! You may recall that in 001 the ball would maintain its Y velocity after colliding with a paddle. You can see how this limits the gameplay somewhat. After a bit of training, it becomes trivial from the agents to predict the path of the ball. Luckily, there is an easy solution!
The ball can now be deflected off the paddle at different angles - depending on where it strikes a paddle. Not only does this force the agents to explore more of the state-space, but it will also add an element of skill to the game.
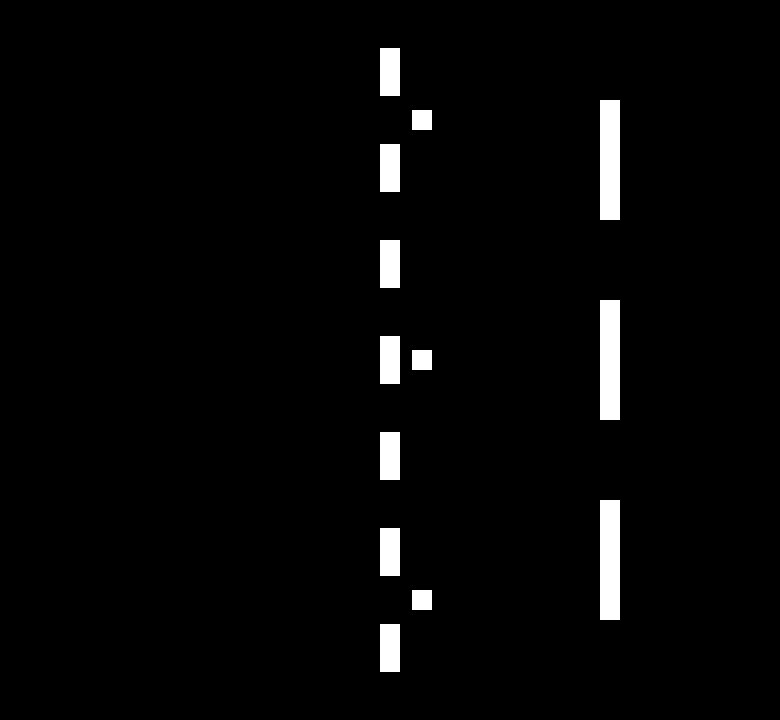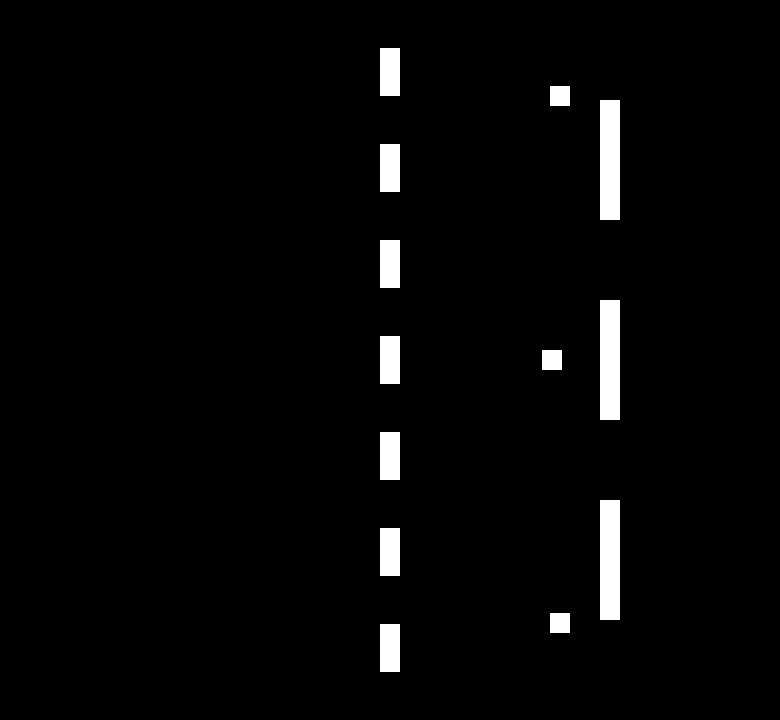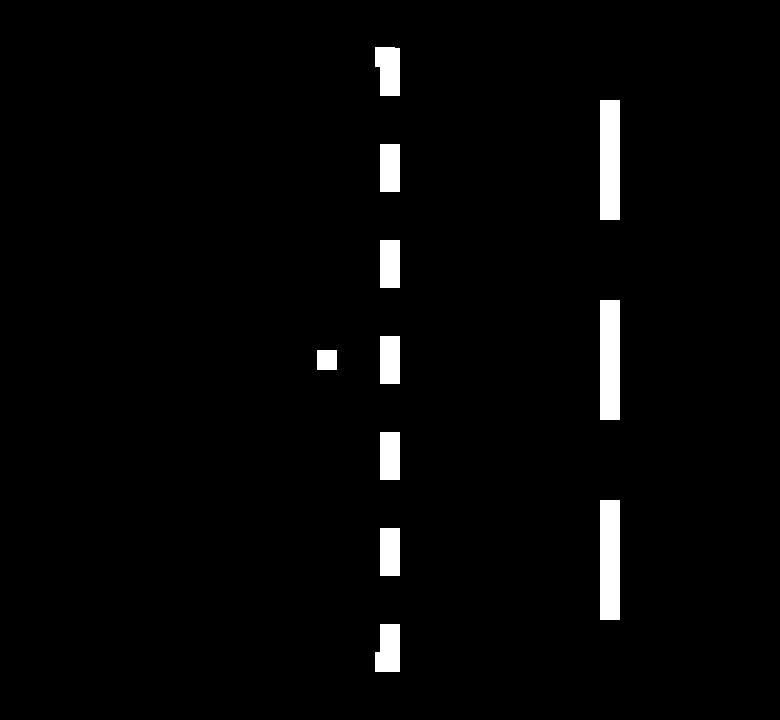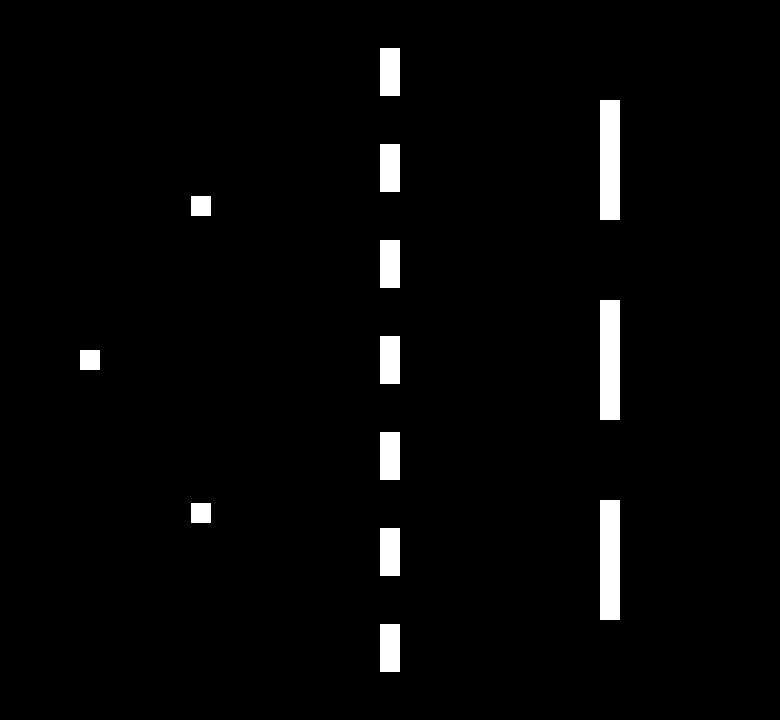
Previously, we trained our agent against a simple conditional AI. Now, this was a good start, but the resulting agent can only be slightly better than the agent it learns to play against. Wouldn't it be great if we could just keep training our agent against increasingly better opponents until it became the best in the world...? Well, what if we could do just that? Introducing Multiagent Reinforcement Learning!
From now on, we will be training two agents at once! One for the left paddle and one for the right. If all goes to plan, both of the agents will improve simultaneously. All we need to do is sit back and watch as the agents repeatedly one-up each other until they have both become perfect players.
Full of confidence, I wrote a new script to conduct 'adverse' learning and hit run. I felt like a genius. Why didn't I think of this earlier? The algorithms were going to do all the work for me!

Well, shit... isn't this an anti-climax... These results don't exactly look like the work of two Pong masters. Personally, I believe that we are under the influence of the curse of dimensionality. Remember that our agent learns by observing the 'state' of its environment and picks actions depending on the state it observers. So, the more states an environment has, the more our agent needs to learn. The curse of dimensionality comes into play when we have so many possible states that our agent can't realistically learn all of them. To help illustrate this, let's have a peek at some numbers.
We define where the ball is by a 19x18 grid; the paddle is always in 1 of 18 positions (like the balls Y coordinate) and we define the X and Y speeds of the ball as being between 1 and 10 speed 'levels'.
When all that information is put together, we see that the environment has 615,600 (19x18x18x10x10) distinct states. I hope that we can all agree that this is FAR too many states. Something needs to be done! But what?
- "We could lower the state resolution. Instead of the ball being somewhere on a 19 by 18 grid, what about 12 by 11?"
Yes... that would lower the space state and is part of the solution. However, we don't want to introduce too much more uncertainty
- "Function approximation?
A fantastic solution, but that would be getting ahead of ourselves. We still have plenty to learn before that.
- "Describe that state observation from the perspective of the agent?"
Ah, now that's an idea that can really take us places!
We currently have 6,156 states to describe the location of the ball and the agent's paddle (PaddlePosition(18) x BallXPosition(19) x BallYPosition(18)). In order to move the paddle to block the path of the ball, the agent doesn't technically need to know where it is. All it really needs to know is if the ball is to it's left or to it's right (and how far away it is). So, we can represent the ball's location as the position of a ball relative to the position of the paddle. Then we don't need to bog down the state space with information on the location of the paddle.
You can see below that the relative positions let the paddle 'see' the ball in the same way across the playing field.
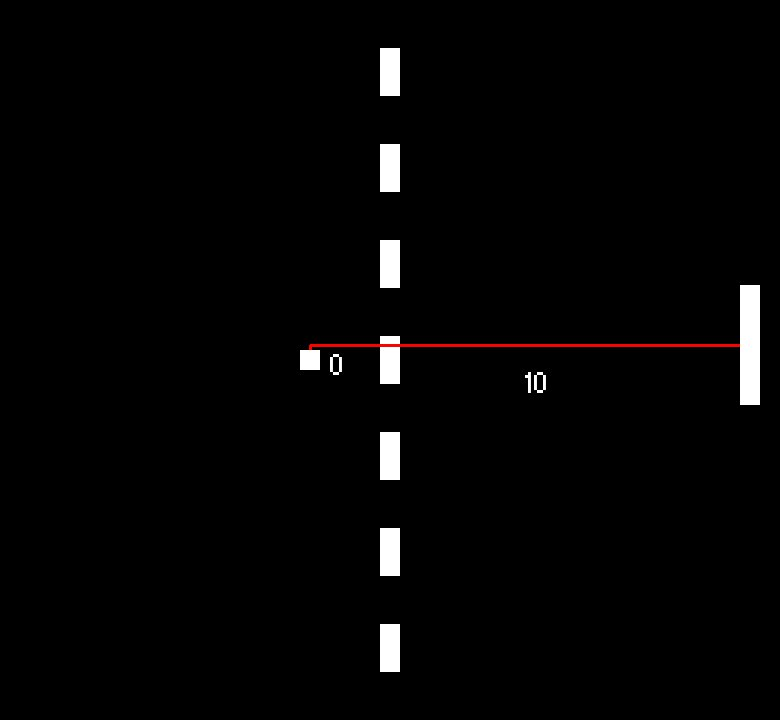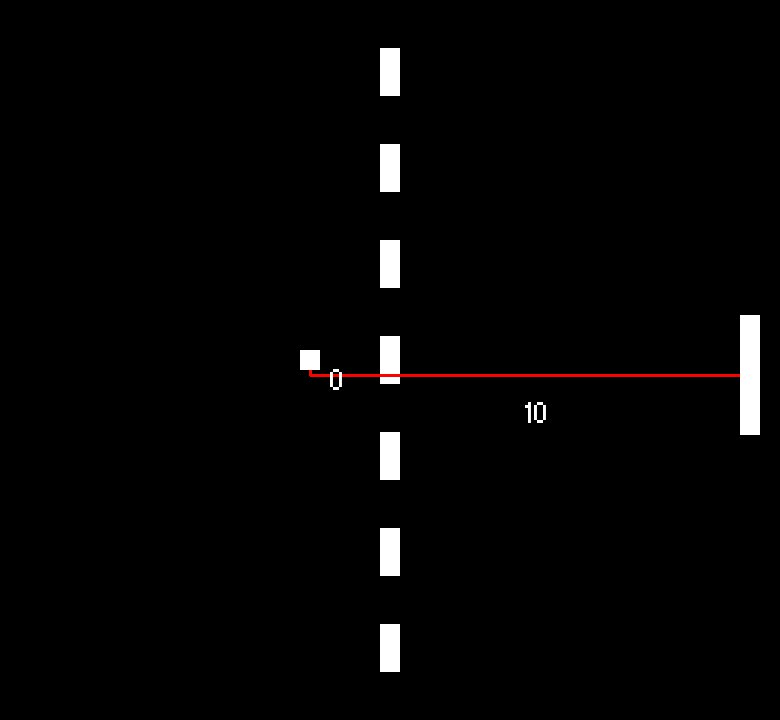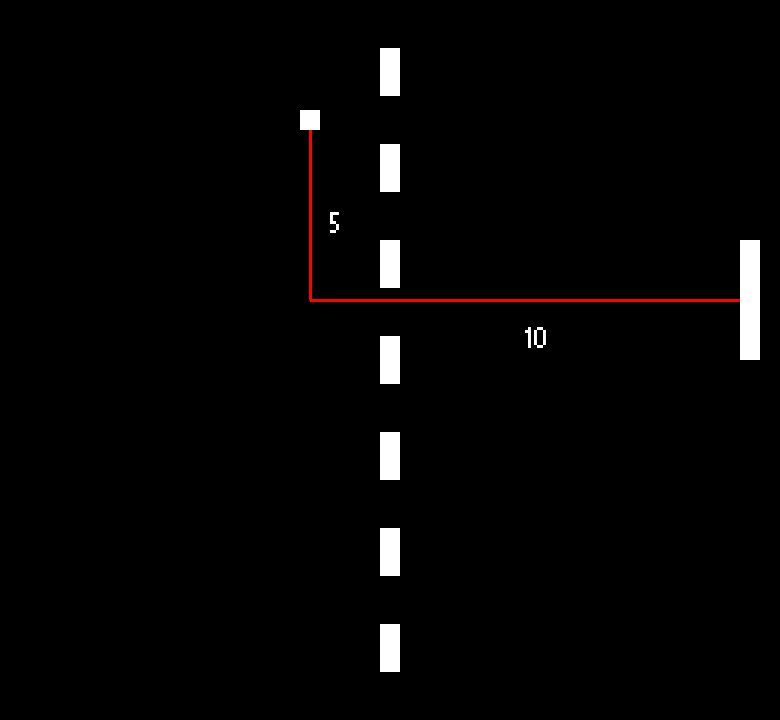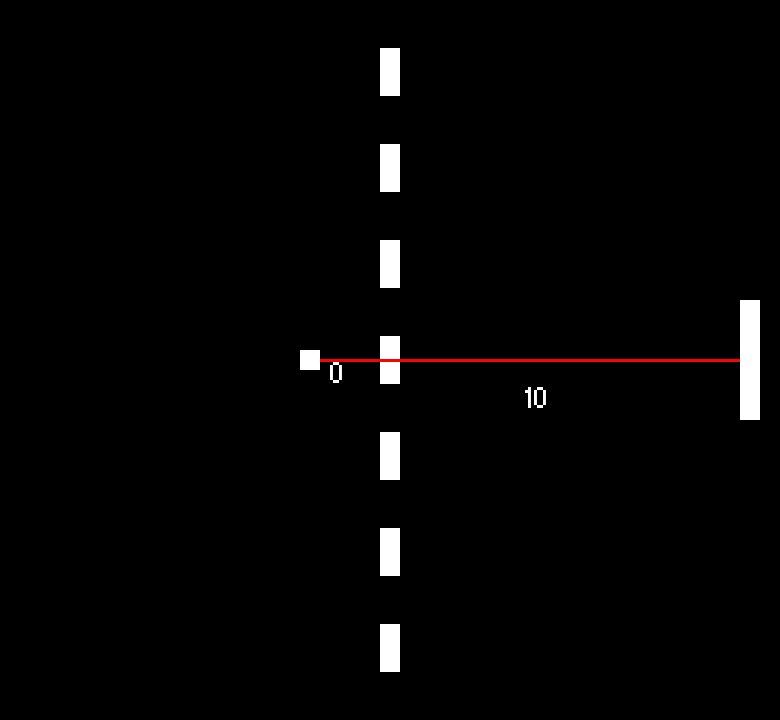
As the ball can be both to the extreme left and extreme right of the paddle, we need to double the number of y positions than before. Even so, we now represent the paddle and ball positions in only 684 states (RelativeYPositions(36) x RelativeXPositions(19)). That is 9 times less than before!
Now, with that out of the way, we are ready! I quickly edited the code and hit Go! ...Oh my god. It is taking ages. As the agents get better, the games get longer and longer. Each episode takes longer than the last. Hours past but eventually:

Ah, much better. We can see that by the end of the training the agents averaged rallies that lasted around 8 returns. So, yeah... that's good, right?
One of the issues with training agents in the competitive style is finding a way to truly evaluate them. We know that they were rallying for 8 shots at the peak of there training but, I would also wager that my nans could string together a decent rally if they got fired up. However, if either of my dear grandmothers were to face Andy Murry, they would likely be bested before they had the chance to offer him a cup of tea and a hobnob. My point is, you can't really know if both agents are truly good until you test them against a known opponent. Perhaps one that has already proven their might in the game of Pong.
Yes. Like many before me, it is finally time for me to face my creation!
It was a noble effort, but there is still a lot of work to be done before our agent can even come close to defeating me! Nevertheless, this was not a wasted exercise, we can learn from this. I'd speculate that currently, the agent focuses more on not conceding a point than does about winning the game. This causes them to opt for safer shots that, in turn, will be easier to return. If we are to improve this agent, we will need to force it to be more competitive. Which is exactly what we will start looking into next time!
Also, once again you can find all the code I have used right here!
