Curriculum Learning
With Unity ML-Agents
Adam Price
July 14th 2020

Introduction
When a person is present with a new problem, they need sufficient background knowledge to solve it. You can’t expect someone to learn calculus without learning geometry first. The same is true for our reinforcement learning agents!
In this article, I will present a challenging game environment and show you how it can be solved using Unity ML-Agents and curriculum learning.
Pursuit-Evasion Game
Pursuit-evasion games are a family of problems that task a group of agents with tracking down members of another group. In our implementation, we will be training a group of 3 hunters to capture a single prey. Each episode, the hunters spawn at the edge of the forest clearing, their goal is to capture the prey before it escapes into the trees!
Reward Signal
We can influence an agent’s learning by rewarding them for completing tasks in the environment. For an agent to be successful during training, we need to define a set of rewards that can guide them towards a solution to the game.


- Capturing the prey (+5). Capturing the prey (+5).
- The prey escapes (-3). If the prey manages to flee into the tree, the hunters will be punished.
- An agent leaves the clearing (-1). This will encourage the agents to move away from the edge of the clearing in training, but the punishment is small enough that it won't discourage the agents from chasing the prey to the edge.
- Each time step (-0.001). This encourages the agents to capture the prey quickly.
Observations and Action
To navigate an environment, agents need to take actions. These actions let an agent directly interact with the environment and are chosen by an agent’s policy. This policy is a function of the agent’s observations that outputs an action for the agent to perform.
Our hunters make and take the following observations and actions:
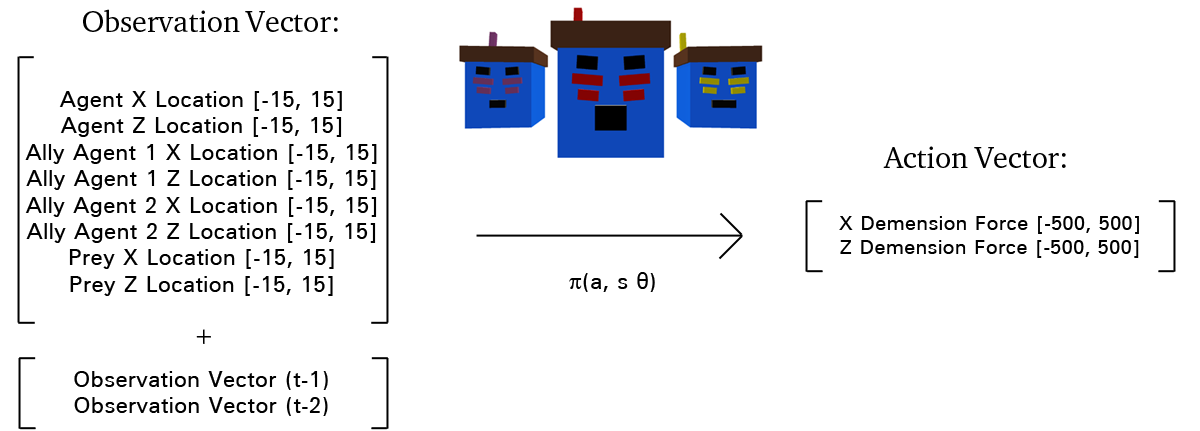
This environment is fully observable, as each agent knows the exact location of itself, the other agents, and the prey. You will also notice that the Observation Vector is stacked, the previous two observation vectors inform the current action to take. Doing this lets the agent infer information on each entity’s velocity.
Our agent’s actions let them push them selfs forwards and backwards on the Z and X planes, giving them full mobility across a fixed plane.
Prey Heuristic
Finally, the last element of the environment is the prey. It is controlled by a simple heuristic that will run directly away from the mean position of the hunter agents. The heuristic is simple, but the agents will have to work as a team as an intersection will be required to catch fast prey.
Training
he agents need to find actions that maximize the reward signal. To do this, we use a neural network as the agent’s policy. Then, during training, the reward signal is used to update the neural network and improve the agent’s policy.
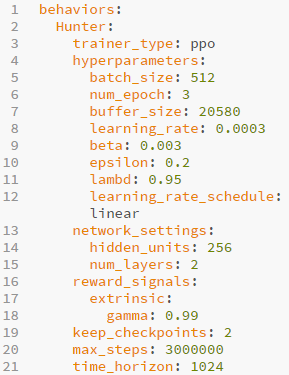
We need an algorithm to handle the training of these neural networks. Thankfully, Unity ML-Agents provides an implementation of Open-AI’s proximal policy optimization (PPO) algorithm.
We provide Unity with a config file to begin training. There are a lot of variables to consider, and each one can have a dramatic effect on training. For information on all of them, consult Unity’s documentation.
PPO is a powerful algorithm, but our environment is too complicated for an agent to enter blind. We need to create a better learning environment for our agents.
Curriculum Learning
Complex environments can require agents to grasp multiple concepts before they can begin to exploit the environment’s reward single. These concepts can be so advanced that random exploration will not be able to reliably reinforce the actions taken to receive a reward. Our pursuit-evasion game is an example of this. The prey can easily evade naive agents, so the hunters will never discover the reward they would receive for capturing it.

This is where curriculum learning comes in!
Instead of letting the agent loose on the difficult environment, we first introduce them to an easier version of the game. From there, we can slowly increment the difficulty with progressively harder ‘lessons’.
The difficulty of our pursuit-evasion game is controlled by two parameters:
- Prey Speed — The scalar force applied to the prey to cause it to move. The higher, the faster it will run away.
- Capture Range — The maximum distance that the hunter agents can be from the prey to catch it.
Our first lesson needs to be very easy; new agents need to learn to walk before they can hunt. We start with a stationary target (prey speed = 0) and a very wide capture range. We then decrease the capture range as the lessons are completed.
Once the agents have fully grasped navigating their way to the prey we can begin to start letting the prey move, at gradually increasing speeds:
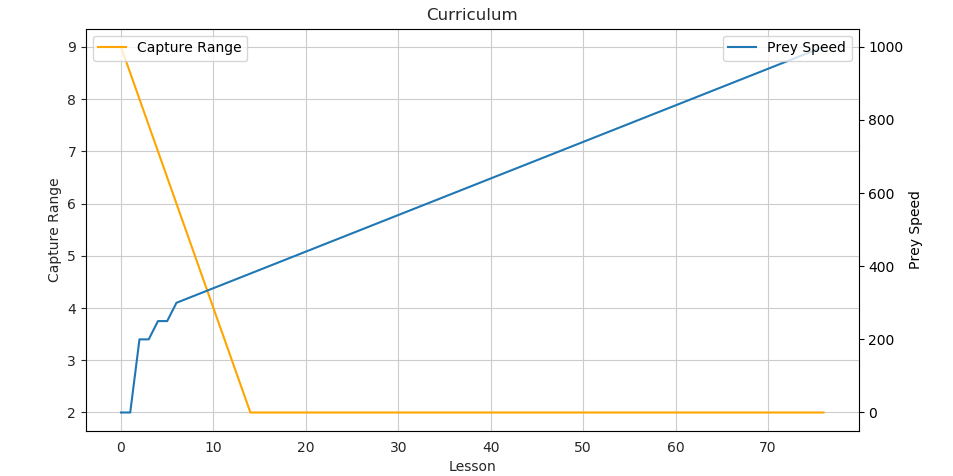
With our lesson plan sorted, we just need to define the criteria for passing a lesson. Luckily, this is quite easy. We consider each lesson ‘passed’ when the agents can accumulate more than a threshold reward value over a set number of episodes. For our training, the lessons are passed when the agents can average over 4 reward per episode for 200 episodes. In practice, the agents need to capture the prey 8 out of 9 times (over 200 episodes) to pass a lesson.
Runtime
We train the agents in a speed-up unity environment to decrease the real-time training time. I trained the agents for 3 million time steps at 2.5x speed. If you want to watch the agents train, then you can watch the video below:
Unity ML-Agents produces many tensorboard graphs to inform us of how the training went, but these two are the most important to us:
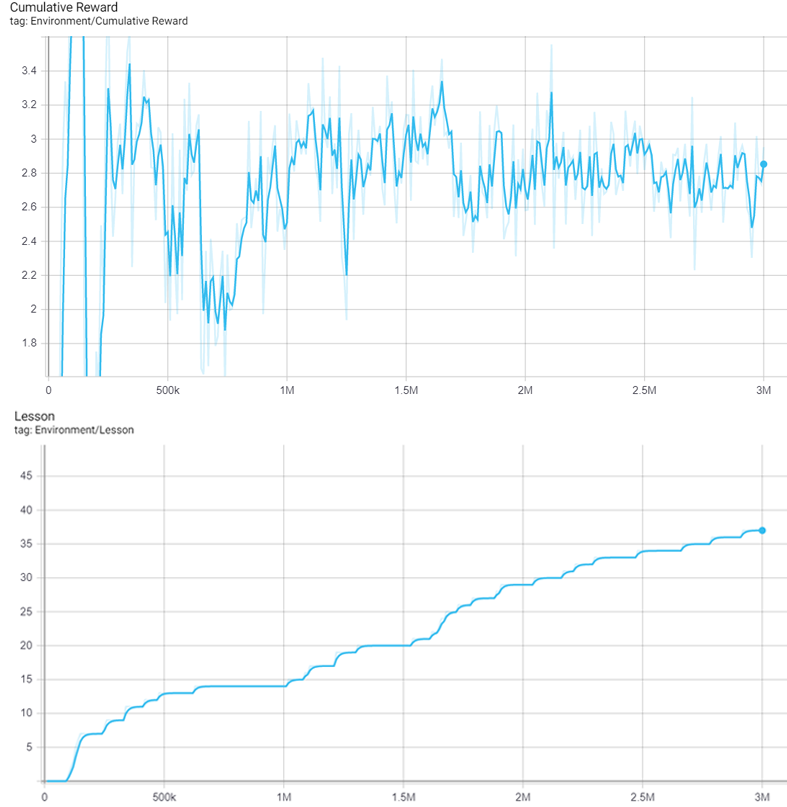
You might have noticed the abnormal learning curve of the reward accumulation. Normally we would expect reward accumulation to keep increasing throughout the training. However, when using curriculum learning, our environment’s reward becomes harder to obtain, so gaining it becomes more difficult. We can still see the individual learning curves of each lesson. Around 600k on lesson 14 is a good example.
Result
We can measure the success of the agents by the number of lessons they have passed. The first 3 million steps of training got them through the first 37 lessons. Unfortunately, this meant that the agents were still faster than the prey, which somewhat reduced the need for teamwork. So, I trained the agent for a further 3 million timesteps. The agents reach lesson 59, the prey is faster than the hunters, so team behaviour emerged.


These gifs show the yellow agent moving to make an interception, while the other two hunters pursue. You will notice that the agents face in the direction they last applied force. The yellow agent has also, effectively, learnt to break. This would be key in intercepting the prey if it adjusted course.
I hope that I have shed some light on the power of a learning curriculum. Even though our learning algorithms have improved drastically over the last couple of years, we still can’t expect them to solve everything on their own.
